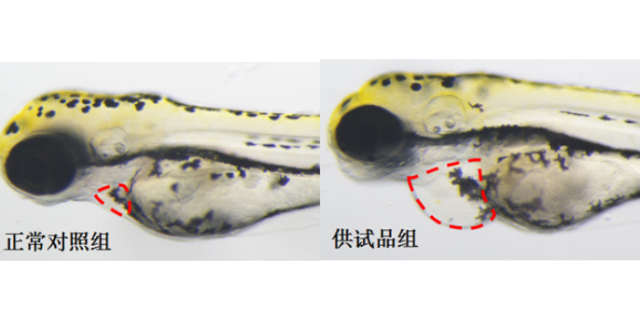
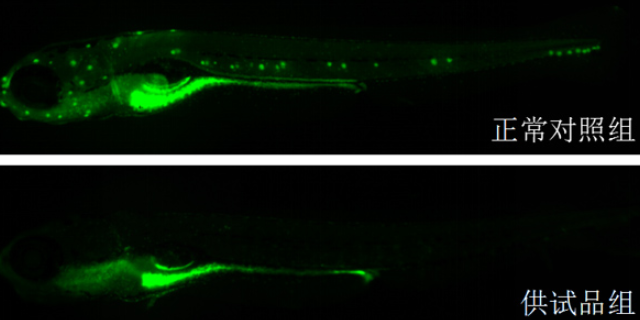
总结现在,2019年的挑选平台网格是NIBR根据平板多样性驱动的子集挑选的首要来源,它可用于50-100个子集挑选,每年在NIBR中有超过5万种化合物用于生化和细胞测验。二维多样性网格根据挑选化合物合集的要害特征:针对尽可能多的靶标的多样性掩盖规模以及根据需要搅扰靶标的恰当化合物特点。这种大小合适的化合物板组的网格为迭代和子集挑选供给了灵活性,然后允许根据分子特性以及化学和生物多样性标准选择板组。从2015年挑选平台获得的一项重要经验是,将溶解度和渗透性作为决议化合物是否有价值的首要决议因素,而不是MW和clogP规模。虚拟筛选在药物发现中的意义。动物模型药物筛选费用

迭代化合物挑选过程如上所述,现在的方针是对界说为空间掩盖方针的类进行迭代,从每个类中挑选排名比较好的化合物样本,然后重复此循环屡次。一旦所有化合物均已按特点进行了排序并分配给不同类型的空间掩盖类别,而且已界说了每次迭代的较小簇巨细,则能够运转挑选算法以生成多样性网格2015挑选渠道和2019挑选渠道的比较图6(分子量)和图7(clogP)展现了2015年和2019年平板子集的特性曲线。2015年的挑选平板网格显现,MW<350Da的偏差很大,A和B类的clogP规模为1-3,使这些化合物简直呈碎片状。我们还发现,2015年筛查平板的A和B类命中率低于C类,即分子量和clogP规模受限会导致整个挑选的化合物多样性失衡。根据这些观察,我们决议更改2019版网格的排名标准:引入高溶解度和高渗透性作为A列的正挑选标准,而MW和clogP不再直接考虑。可是,为了同时取得杰出的浸透性和溶解性,较低的MW和clogP仍然是有利的。如图9和图10所示,与其他两列相比,2019版:高溶解度和浸透率色谱柱的MW和clogP散布已移至较低值。更重要的是,2019版的新设计还似乎对前两列和行中的化学起始点产生了积极影响。发育生物学药物筛选高通量筛选的不同使用场景。
创立挑选渠道多样性网格如上文针对挑选渠道的规划所述,咱们主要考虑了两个方针:方针是比较大化挑选渠道子集的多样性。生物活性空间的多样性是咱们的主要方针。对于化合物,存在大量的描述符和多样性指标,其中有些是部分剩余的。没有简单的方法能够将它们组合为一个一致的指标。因而,咱们做出的挑选是单独运用几个相关度量,以通过聚类为每个度量定义复合类。其他化合物的分类由现有的离散化合物注释产生。一旦将化合物分为生物活性和化学结构类别,多样性挑选过程的目的就是生成较小尺度的子集,确保每个类别的预设较小覆盖率。第二个方针是优化化合物的特异性和主要的理化性质,因为要考虑多种此类特点,因而需要将它们组合成一个多方针得分。这样的打分是每种化合物的单独特点,答应在单独的基础上对化合物进行比较和排名。
2021年7月16日,DeepMind团队在Nature上公布了AlphaFold2的源代码。一周后,DeepMind团队再发Nature,公布AlphaFold数据集,再次传开科研圈!AlphaFold数据集覆盖简直整个人类蛋白质组(98.5%的所有人类蛋白),还包括大肠杆菌、果蝇、小鼠等20个科研常用生物的蛋白质组数据,蛋白质结构总数超越35万个!并且,数据会集58%的猜测结构达到可信水平,其间更有35.7%达到高信度!深究AlphaFold2计算模型发现,AlphaFold2没有学习AlphaFold运用的神经网络相似ResNet的残差卷积网络,而是选用近AI研究中鼓起的Transformer架构,其间与文本相似的数据结构为氨基酸序列,通过多序列比对,把蛋白质的结构和生物信息整合到了深度学习算法中。从模型图中可知,AlphaFold2与AlphaFold不同,并没有选用往常简化了的原子距离或者接触图,而是直接练习蛋白质结构的原子坐标,并运用机器学习方法,对简直所有的蛋白质都猜测出了正确的拓扑学的结构。计算AlphaFold2猜测的结构发现:大约2/3的蛋白质猜测精度达到了结构生物学试验的丈量精度。蛋白质与高通量药物筛选化合物库。

此外,可用的机器学习模型在根据2019版推断的生物活性的分类基础上扩展分类选择中发挥了要害作用,然后减少了化学骨架分类在分类选择中的主导地位。具体而言,增加根据化合物库的参阅活性概况聚类,使咱们能够在挑选过程中增加生物活性信息的权重。总体而言,咱们认为咱们的2019年根据平板的筛板可以实现多样性驱动的子集和迭代筛选,而且当时的设计在筛板中提供了均衡的化合物分布。新药的研讨开发是一项投资较大、周期较长、风险较高的高技术产业,经常要面临大量错综复杂、互相矛盾的数据,每个决议都可能使多年研发成果付之东流。针对新药研发高通量筛选1小时究竟能挑选多少样品?高通量大量筛选
高通量药物筛选的意义有哪些?动物模型药物筛选费用
单个生物靶标类。有关单个生物靶标的生物活性数据是从咱们的内部系统“hithub”中提取的,该系统包含一切内部生物活性数据,并定期经过来自主要公共数据源(ChEMBL,ClarivateIntegrity,GOSTAR)的生物活性数据进行更新。生物化合物概括空间类。按单个靶标对化合物分组的一种补充方法是跨多个靶标或分析使用生物学谱数据。猜测配置文件是在单个目标基础上核算的,以依据pfam数据库中的蛋白质域注释取得贝叶斯活性指纹(BAFP)以及每个蛋白质家族来取得贝叶斯域指纹(BDFP)。化学空间掩盖类。NIBR开发了一种化合物骨架分类方法,称为“骨架树”,随后扩展到了“骨架网络”。该网络用于纯粹依据化学结构来界说类别。手动分类。以上一切分类都是经过核算得出的,还需要有依据化学家们的经验常识来指定的分类。动物模型药物筛选费用